


Alibaba launched Qwen3 AI, again challenges Chatgpt and Google Gemini
Alibaba on Monday announced a family called Qwen3 to a family of AI model, claiming that it is better than Openai’s chat and Google’s Gemini AI model in some cases.
Listen to the story

The Chinese tech company on Monday announced that it has launched a new family of AI model, called Qwen3, which is better than Openai’s Catgpt and Google’s Gemini AI model. The company shared a long post on X, revealing its new AI model. “We are excited to announce the release of Qwen3, the latest addition to the QWEN family of large language models. Our major model, Qwen3 -235B-A22B, coding, mathematics, general capabilities, etc. get competitive results in benchmark assessment of coding, mathematics, general capabilities, etc., when other top-tier models such as other top-tier models such as Deepsek-R1, O1, O1, O1, O1, O1, O1, O3-D.N. Sent.
Alibaba says the Qwen3 AI models support 119 languages including Hindi, Gujarati, Marathi, Chhattisgarh, Awadhi, Maithili, Bhojpuri, Sindhi, Punjabi, Bengali, Oriya, Magahi and Urdu.

QWEN3 has eight models from 0.6B to 235B parameters. These include both the dense and mixture of experts (MOE) architecture, designed to meet various performance and efficiency needs.
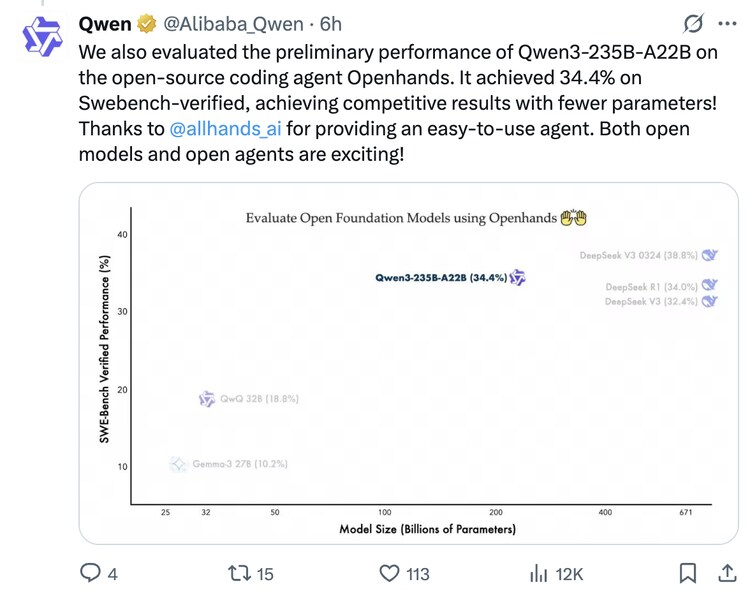
According to Alibaba, the top performing model gives strong results in major benchmarks such as Qwen3-235B-A22B, mathematics, coding and general arguments. “Chhota Mo model, Qwen3 -30B-A3B, detects QWQ-32B with 10 times of active parameters, and even a small model like Qwen3-4B can rival the performance of Qwen2.5-72B-Estruct,” the company claims. Compact Qwen3-4B rival very large Qwen2.5-72B-insstruct.
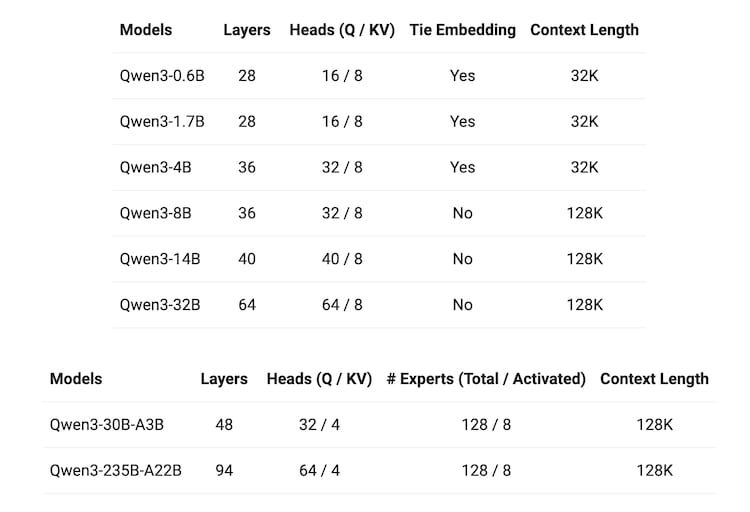

“We are opening two Mo models: Qwen3-235B-A22b, a large model with 235 billion parameters and 22 billion active parameters, and Qwen3-30B-A3B, a small Mo model with 30 billion total criteria and 3 billion active parameters. QWN3-I-4B, under APACHE 2.0 license. Qwen3-1.7B, and Qwen3-0.6B, “The company writes in its blog post.
These models are available on embracing the face, modelcop and kaggle with both pre-educated and post-appointed versions (eg, Qwen3 -30B-A3B and its base variants). For signs, Alibaba recommended SGLANG and VLLM, while local use is supported through devices such as Olama, LMSTUDIO, MLX, LLAMA.CPP, and Ktransformers.
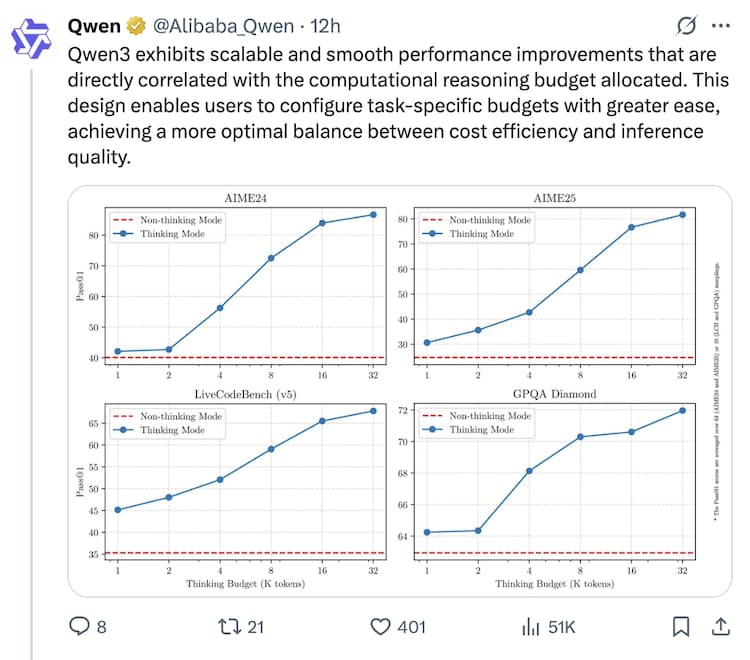
Alibaba says the Qwen3 models offer scalable performance, which means they can accommodate the quality of the response on the basis of the calculation budget, to enable an optimal balance between speed, cost and capacity.
They are well suited for coding functions and agent-based interactions, with better multi-step logic.
Alibaba says that the Qwen3 model also comes with something called hybrid thinking. There is a thinking mode, which processes the information before the final answer, which takes time. Then there is a non-thinking mode that allows the model to produce immediate reactions, prefer to speed at the depth. This dual-mode system gives users control over the depth of calculation based on the function.
Says Alibaba, “This flexibility allows users to control how much ‘thinking’ performs based on the work in the hand of the model.” “This design enables users to configure the more easily a specific budget, receives more optimal balance between cost efficiency and estimate quality.”